TIME TO RUN THROUGH THIS GUIDE AND GET USEFUL DATA: Under 10 minutes.
This guide is intended for those that are interested in harnessing the power for Google’s NLP APIs and want to understand what topics are missing from their content. The end product of this guide is a technical analysis of what topics your content covers vs. what topics competitor content covers.
Google Natural Language APIs
Google Colab
Python
What’s required:
Zero technical background
Creating Google API credentials
The ability to copy & paste
The output is a nice .csv file that you can give to your content team and let them know what other pieces of content are still needed to be included or may be missing.
As always, this guide is not perfect. If you have questions, the best place to reach me is on Twitter (@oops89). Anyways, see the below:
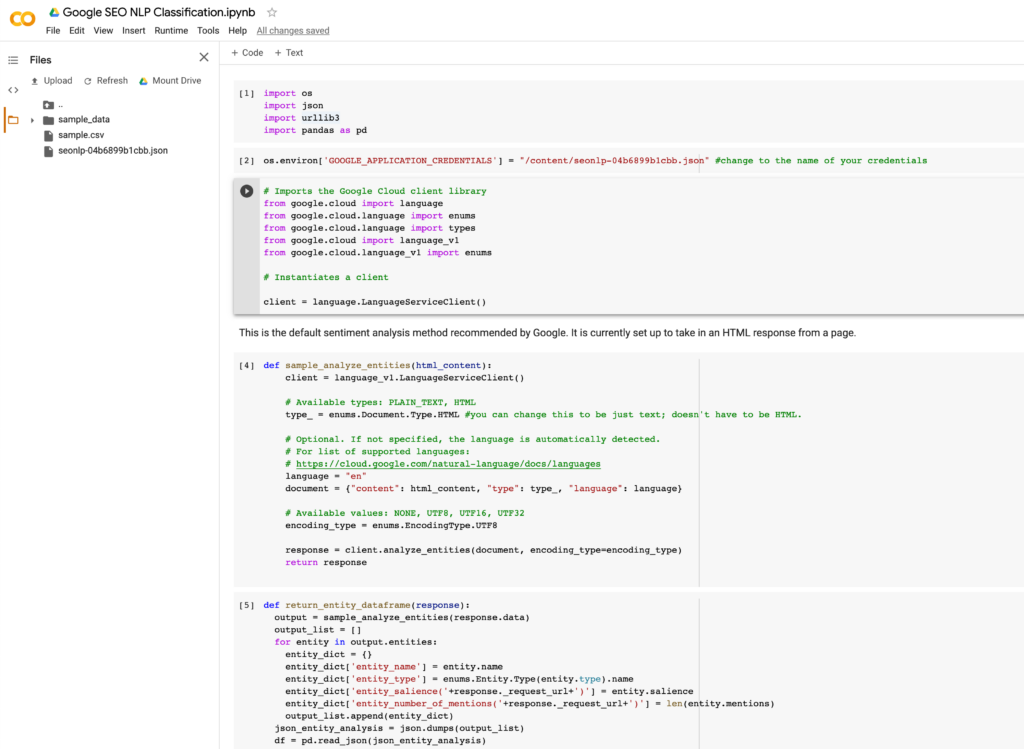
This is a code page of Google’s Colab framework which lets your run code FOR FREE on their cloud machines without ANY significant overhead. What this means for you is NO SET UP OF ANYTHING – IT JUST WORKS. When you click this, it should take you to a page that looks like the below.
Click play on the very first line of code – this should initialize the initial pieces of software that you’ll need.
Once you’re in, click on File & “Save a copy in Drive” – you won’t be able to make edits to my version.
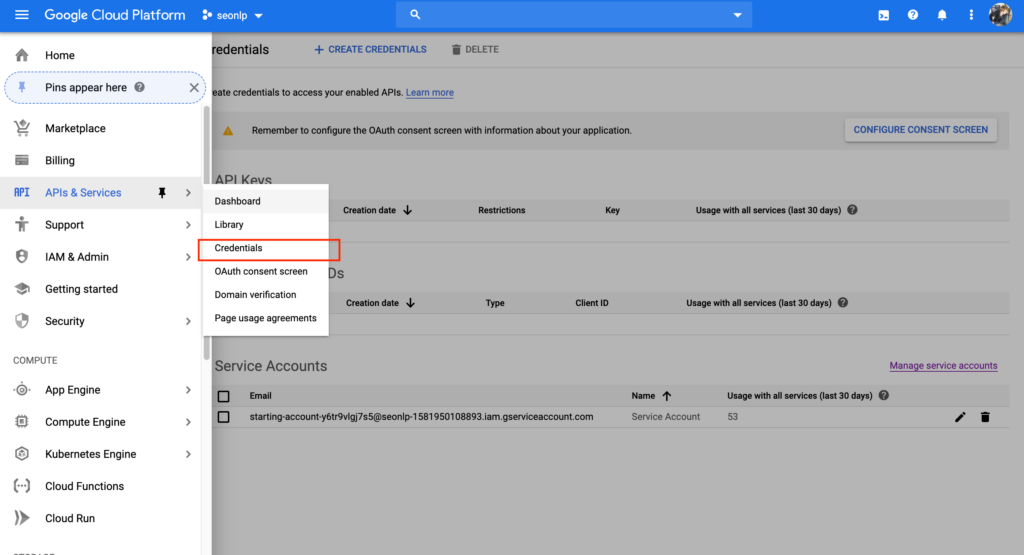
Once you set up the project, you’ll need credentials. The way to get to credetials is to click on the hamburger menu on the upper left-hand corner then API’s & Services > Credentials.
Click on “Manage service accounts” and follow the steps to create a service account. At the of this set up process you should be given a .json file that will serve as authentication.
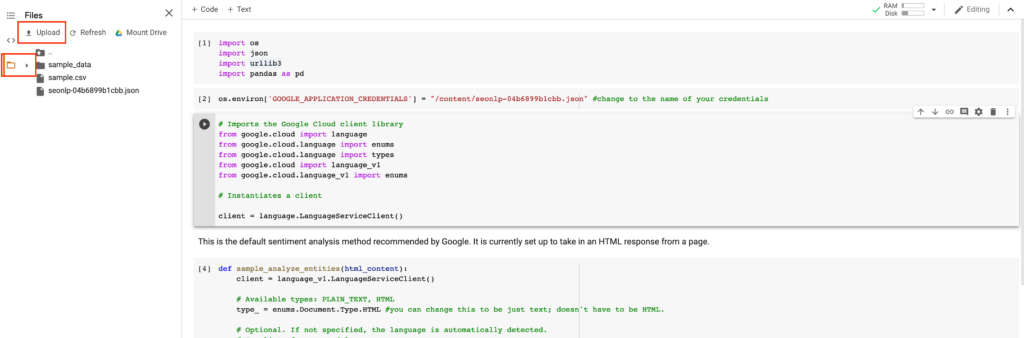
Jump back to the Colab window and click on the folder and then click on “Upload”. Upload the .json authentication file.
Change line 2 in the Colab notebook to exactly match the file name of your .json file. This is important to get right because this is what it is used for authentication.
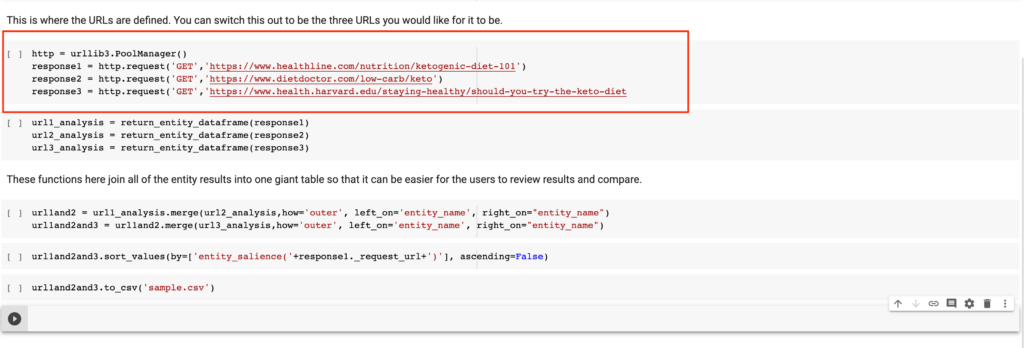
Keep hitting play until you get to the below. This is where you’ll need to put in the URLs that you would like to use. By default, I used three articles that are about the keto diet as an illustrative example – feel free to make this whatever you need.
Once set, continue to hit play. What’s happening now is that the notebook is going to those sites and fetching the HTML on those pages.
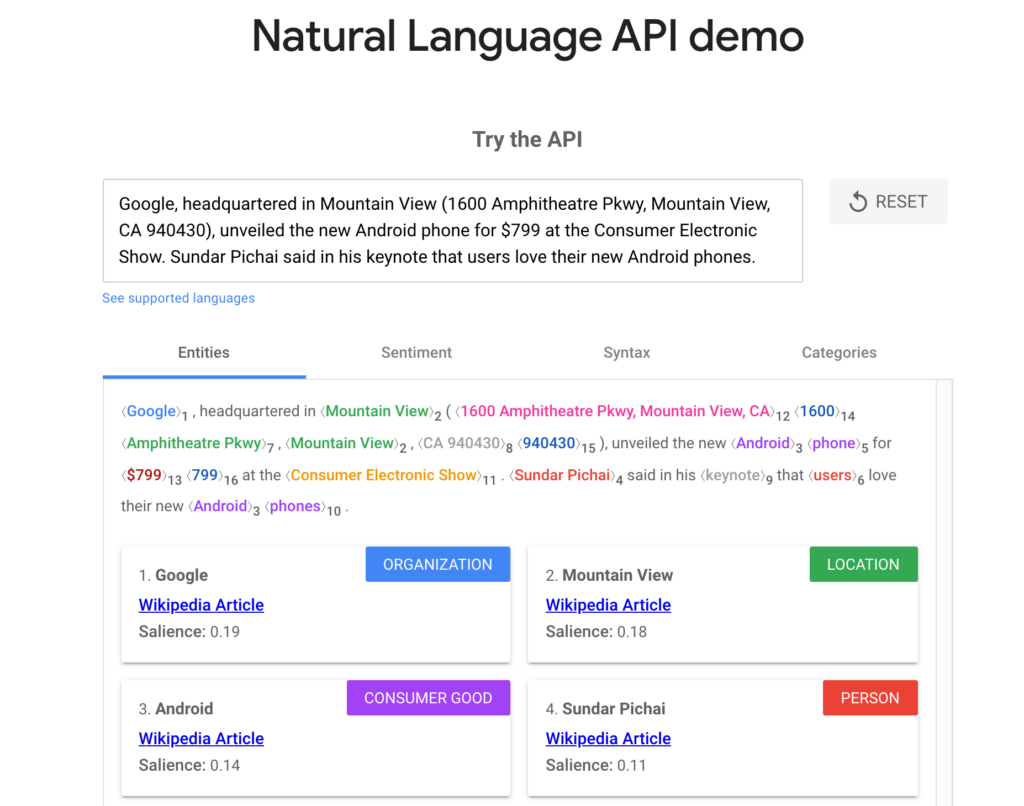
Step 7 in the guide, is actually where the API magic happens and when the NLP API is being hit. The results are all put together into one table that makes them readable.
Continue to hit play and you should end up with a .csv file called sample.csv. On the left-hand side left click on the file and download it to your computer.
Boom – you’re done with the guide and have actionable data! Now to explain how to use the output. After opening the csv, I recommend sorting largest to smalles on the first “entity_salience” column. The return output is a series of columns organized by the following:
Name of topic (entity name) – this is the central topic that the NLP API has understood. In this example – the dominant topic was “diet”.
Entity_salience (URL used) – The salience score for an entity provides information about the importance or centrality of that entity to the entire document text. (this is the Google definition). For us, this is really important because it’s the algorithmic understanding of how important this was to the whole piece.
Entity_number_of_mentions – this the number of times the topic is mentioned in the text.
Entity_salience for the 2nd & 3rd URLs
Entity_number_of_mentions for the 2nd & 3rd URLs
A content producer should be able to look at this data and understand the following with data informing their decision instead of only gut feel:
Are there any topics that they missed?
What is the centrality of the topics that the others had discussed?
How often are others mentioning certain topics in their content?
This method is not perfect and has some known drawbacks that I’ll list below:
Very random topics such as precise numbers are listed as “topics” by Google’s API. Luckily they have a very low salience score and can be ignored.
When analyzing HTML, pop-ups and navigation text becomes a problem and is included in the analysis sometimes.
There is no child-parent relationship defined in the API response in connection to certain entities.
As always, reach out on Twitter if you have any feedback.
Working with several clients or deeply on one domain in SEO can be very stressful during any of the frequent Google organic search algorithm updates. The data from Google Analytics only tells you that traffic is either up or down and the data from Google Search Console is extremely difficult to pull – especially for several clients and quickly. This is a guide that will help you quickly compare Google Search Console analytics data (clicks, impressions, reported CTR, reported position) between two dates and export the results into a .csv file.
This guide uses the following technologies:
Python
Google’s Webmaster API
Jupyter (an open-source framework for data analysis)
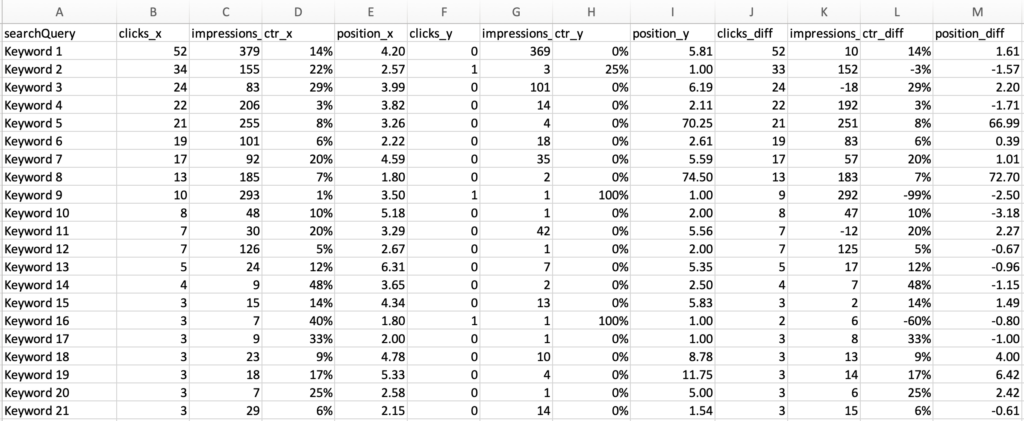
The end result should be a nice .csv file that looks like this (I redacted the keywords in this case :), the end result has real keywords, I promise):
Before getting started, you’ll need to download the code here (https://github.com/odagayev/jupyter_GSC).
Part 1 (this is for Python novices or people that are not proficients coders yet!)
Install Python3 & Pip – this is actually a lot harder than it needs to be for folks just starting out. I don’t fully have a grasp on all of the dependencies and permissions so I’m gonna link the guides that I found useful during my experience.
Part 3 (Running your first-time code) – old-timers can skip to Part 4.
Type the following to install all dependencies on your machine in your terminal:
pip install -r requirements.txt
This should kick off a ton of installations of dependencies.
Launch the Jupyter notebook by typing jupyter notebook
You should see something that resembles the following address in your terminal console: 127.0.0.1. Copy and paste that address into your address field in your browser. You should see something like the below in your browser:
Click into the “GSC Performance Between Two Dates.ipynb” file.
A Jupyter Notebook works on a step by step basis. It works by going step by step through each “cell”. This makes it great for working with data and I think makes it easy for novices to follow code as it is being executed. Update the project folder value as is shown in the screenshot below and either create a .env file with the CLIENT_ID and CLIENT_SECRET values or paste those values directly into the script. If you’re pasting the values directly into the script put a # value in front of the project_folder & load_dotenv lines in cell 1.
Click on the generated link and you should be taken to an authentication screen by Google. Complete the authentication and copy the code and paste it into where it says code = "" in between the "". Hit run until you get to the target domain step. In the code you have everything set up to make an API call at this point. Below we’re going to configure the actual request!
In between the parenthesis at target domain enter the domain you are targeting. Make sure to include the appropriate protocol and whether the domain is on www. or not. Lastly, make sure you actually have access to this domain in Search Console.
Within the API request parameters, I outlined where to input values for dates and what dimensions you want. I recommend keeping this request as is on your first time through the process so that you can get the hang of it.
Continue to hit Run until you get to test_response and run that cell. You should see a JSON object of the response and recognize the data. Conversely, if something got messed up during credentialing or creation of the request you should see an error message returned.
The next cell puts the JSON response into a dictionary and then the cell after that puts it into a nice table (this is called a pandas DataFrame in Jupyter speak but for our purposes, this is just a table).
Part 4 (understanding the difference)
The next five cells define a function that iterates over the returned data and makes several requests so that you can get all of your search data out. This is done because Google only returns up to 25,000 data points at a time. So for larger sites, we’re making several requests until we don’t get 25,000 data points.
In the cell titled request1 , you should see something very similar to the sample request we’ve made early in the notebook. This is the request where we are defining our first date range.
In the cell titled request2, change the values of "startDate" & "endDate" to the appropriate values for the second date range that you would like to use.
Continue running the notebook and you should see that you have produced two data frames, one for each of the defined date ranges aggregated on the search query. Please note that I’ve used the following aggregation methodology:
Clicks – sum (I’ve added all of the click volumes for the given date range)
Impressions – sum (I’ve added all of the impression volumes for the given date range)
CTR – average (I’ve averaged the CTR values for the given date range)
Position – average (I’ve averaged the position values for the given date range)
Once you get to the merging step the two data frames that you’ve produced become merged using an inner join. This means that any of the keywords that are not in the 2nd date range but ARE in the 1st date range will be dropped from the new DataFrame. This shouldn’t affect 90% of use cases but if it affects yours, I’ve added guidance on how to address this into the notebook itself.
Continuing running the code and you’ll see that we do all of the calculation right in the notebook before giving you the option to export the results to a csv. Just FYI, in this guide – the clicks x numbers represent the data made in request 2.
I’m publishing this in February of 2020 so the wounds have begun to heal from Matarritas’ tackle but I’m still picking at the scabs. Looking back at 2019, the feeling I remember was beating Atlanta 4-1 at home and telling my friends on the subway ride back into the city – “if we get the 1 seed, we’re not losing at home. Make sure you don’t schedule anything for the MLS cup weekend because we’re going to LA and we’re gonna win the fucking cup. Dome is gonna figure it out. Ring is gonna do Ring stuff. Taty is gonna do Taty stuff. Sean John saves. ” I never felt like we were the best team in the league or the juggernaut of the conference but the home field was going to carry us to the cup. Losing to Toronto felt like a gut punch in so many ways but it was easy to rationalize until we saw LAFC go out next weekend. LAFC losing is what truly hurt because I realized what truly could have been; the road to the cup wasn’t even as herculean as I thought it would need to be. Turns out we didn’t need to be Herculean to win the cup in ’19, we just needed to be ourselves.
My overall mood with the club is entrenched. I’m over the pessimism about the stadium. I’m over the pessimism about CCL, it is what it is – it seems like the issues weren’t at the NYCFC level but at the CCL level not willing to certify the other stadium options. At the end of the day, there is no better way to spend two hours in NYC on a sunny June day/night. I love going to the games, stadium be damned. I love that we’re starting to build through the academy. At the end of the day, yea – I know there are things that are holding the club back. Yea, the sightlines suck. Yea, you can’t fucking see when someone takes a corner from left side if you have bleacher seats. The declines in attendance are sad to see but it feels like the true fans are still here. We’re still reading The Outfield, we’re still circling Red Bulls away on the calendar, we’re still staying up for the west coast games and taking the unbaptized to the games.
Going into last season, early on – I expected them to be at the top of the East. I trusted the transfer strategy – CFG always pulled people out of their ass that I’ve never heard of – that’s the benefit of being a member of the Galactic Empire. I read as much Mitrita’s propaganda as possible (thank you Google Translate). I convinced myself that Medina was going to take a step forward (thank you my absolutely delusional brain) and that we still had Maxi. I didn’t replace the giant 5 foot 9 Spanish striker sized hole in my heart, but I learned to live with it. The pundits said that NYCFC would suck – I didn’t care, we still had the core, we had Dome, trust the process.
So turns out the pundits may have been right, at least at the start. The start of the year sucked, especially for a #DomeIn supporter. In retrospect, the 2-2 vs. LAFC was a much bigger result, especially given how well I thought we played – that should have given Dome a bit more slack. However, the 2-2 at Orlando, 0-0 vs. DC, losing 4-0 @ Toronto, and lastly the inexcusable 0-0 draw at home to Montreal were incredibly frustrating results at the time as they are now looking back at them. The team at home never seemed to finish. The team away never seemed to care. The away performances were especially stupefying because it was as if you were watching someone playing FIFA for the first time and not knowing about the turbo button. We were so slow and we couldn’t string passes or opportunities together.
The next match, the beginning of a new era for Minnesota, should have been the end of the Dome era but a young Argentine proved to be the spark and the boys got it done. NYCFC held 66% possession, outshot Minnesota, and should have had all three points if it wasn’t for Sean’s untimely gaffe. This was a stunning result considering a Minnesota team full of adrenaline upon opening a new stadium and NYCFC being a side that lost 4-0 in its previous away match. Taty leading the turnaround really kickstarted his entire season and set the tone for what he was going to bring to the team.
The change that sparked it all seemed to be going with a 3-5-2 with the outside backs (Mata & Tinner) having a lot more freedom to make forward runs while the two defensive minded central midfielders (Ring & Ofori) were operating a double pivot. This style seemed to fit the roster because of the more direct offensive responsibilities to the more offensive minded outside backs on our roster and handing much more direct defensive responsibilities to the defensive central midfielders and the rock solid back 3 (read more at the Outfield here).The trickle down effects of letting Mata & Tinner make runs with more freedom were immediately evident.
The DC match was going to be proof that this was no fluke and the boys delivered again. They completely dominated the game at Audi field with the new signings, Heber & Mitrita, leading the charge. The Chicago and Orlando home results that followed (1-0, 1-1) were frustrating but expected given the wear on the team of playing so many games in a short period of time. The boys in blue really returned to form with back to back 2-0 results vs. the Impact and the LA Zlatans (completely neutralizing him).
A realization at this point of the season was how freaking good Sands is. Dome had the cojones to put a teenager against Zlatan… and it worked?!!? Sure Chanot and Callens were there but Sands was the anchor in the middle of the pitch holding the LA Zlatans to only one shot on goal. The fan base knew that the academy had already started paying off dividends. Sands represents the start of the academy movement that will hopefully transform the team for years to come.
June & July were extremely busy months with NYCFC finally getting its first US Open win but also it’s first home loss with a bad 1-0 loss to Portland. The loss at Orlando in the Cup was discouraging but ultimately it was for a minor cup and it was nice of NYCFC to let Orlando win something for once. None of this mattered because Red Bulls away was coming up.
NYCFC started off so well with Heber doing what he was brought in to do, but then the carriage turned back into the pumpkin, even with Johnson making some RIDICULOUS saves. NYCFC lost 2-1. Not all was lost, NYCFC still had the game at Yankee Stadium, but this would have spoken volumes that NYCFC was not going to be the NYCFC of years’ past.
August & September brought more of the same. We cruised at home and had some difficulties reproducing the same results away. Taty had cemented himself as a deadly force in the MLS and as our spark plug with an incredible off the bench performance vs Houston scoring twice in the last ten minutes to get three points for the boys in blue. The aggressiveness he displayed all season was epitomized in this match and it proved to be another feather in the cap of the CFG scouting network.
There was some drama surrounding NYCFC securing the top seed in the East but the other results fell into the place and we were spared some true decision day drama. At this point, the road to the final seemed pretty straightforward.
There was the lingering question about Medina, this was the last nut for Dome to figure out. He did try to include him in the XI and bring him off the bench but it was just a jigsaw puzzle that was too hard to solve. There was one glimmer of hope in a game vs. New England where Medina scored both goals and led the effort to come back and secure all three points at home. This still remains a sword logged in the rock for another manager to figure out.
Although we now know that the Astros did literally everything in their power to try to sweep the Yankees; NYCFC having to play in Citi Field is overblown as a factor that possibly decided their fate. The pre-match atmosphere was electric, the fans were in, the field was in great condition – there was no reason we should have lost that game. Single-game elimination is cruel, but it’s what we have. Our seats were underneath the Pepsi Porch and after the Shradi goal, the crowd was going so crazy that one of the support beams was literally shaking. I don’t think the atmosphere is the problem. Again, we’ll never know why what happened had to happen, but it did and we should move on. We need to face the fact that although we were a good team last year, we weren’t great. We were riddled with inconsistency and were way too Maxi dependent to be a true juggernaut – over two legs, do we get it done? Probably. Am I sure? No.
Thinking about that playoff game, I’m not sure exactly what needed to change. I loved the XI that Dome put out there. I watched the highlights while writing this, the first half was literally all Toronto shots, the mistake at the back was uncharacteristic but Toronto was peppering the steak and we were seasoned, the goal had to be. The second half was thoroughly dominated by NYCFC who have always played well in the second half. If I had to reverse one thing it would be to have Ring take a step back from being involved in the offense and just be entirely focused on being the cleaner on the defense. Keaton is massive but does not play to his size while Maxi already has too much responsibility on the offense, you can’t ask him, especially at his stature, to take a bigger defensive role. Also, I can’t help but think what would have been if Villa and NYCFC saw eye to eye on one more year and the 7 train came off the bench in the 81st minute in that game… you HAVE to believe he would have just found a way to get it done the same way he got it done vs. RB 3-2.
Going forward, on the defense – I don’t know how much better NYCFC can get than the trio of Chanot, Callens, and Sands. Sands is only going to continue to get better while Chanot and Callens are going to continue to be rocks on the defense. I’m not sure that Thórarinsson is an upgrade here but I think the club has gotten him purely for depth, the transfer value seems to imply a mid level option but who knows… maybe this is another gem found by the CFG scouting network.
Tinner and Mata should remain in more offensive outside back roles. With Tinnerholm entering the prime of his career I don’t see any reason for why we should expect a regression from being one of the best outside backs in the league. With Mata, I just don’t know. His first impressions years ago showed so much promise, I thought that there was no chance that we would keep him from Europe. He clearly has the talent and the pace to do more and my hope is that we see some more of that on the pitch. The tackle vs. Toronto can hopefully be the first scene in the MLS Cup Champs DVD this year.
Ibeagha has been very trick or treat last year. I think he has all of the tools to put it together but I would hope that he’s doing it in less precarious positions than the center of the pitch. With his pace hopefully we only use him in outside back roles where there is a chance that his mistakes may be covered up by the stalwarts of the defense in the middle.
I’m very excited for the arrival of Gray into the first team and am hoping that Ronny figures out a way to get him some playing time. I loved what I saw in the pre-season, he seemed to have the poise and presence that will hopefully prove to be extremely useful to the team. I’m also hoping that there is some natural chemistry between Gray & Sands due to their time in the academy together. I would much rather that Ronny play Gray over Scally purely because I would prefer that we spend match time developing players that are going to be on NYCFC next year.
For the midfield, the big question mark is of course the continuing presence of the man that makes everything go. Maxi is going to be 33 this year which is usually the age at which physical gifts start to decline. Maxi’s 20 assists and 7 goals account for 42% of NYCFC’s goals – it’s important to note that he only started 28 games so that number is probably closer 50% if we’re just counting the games where Maxi played, even higher if he put some of those penalties away. In any professional organization it’s a bad idea to depend on one individual for 50% of the production. The club hasn’t done anything in the transfer market to de risk this situation. Haak, Ring, and Rocha are too defensive minded. Torres and Parks are still young so it’s possible but the management team must be seeing something in training from them that we are not seeing on game day. Of course, there is always the Medina possibility… but let’s be real something would need to be drastically different for this to work out.
On the defensive side of the midfield, I wish we had some depth behind Ring. He’s played in 61/64 games over the past two years and we don’t have anyone that comes close to his presence. The amount of crucial tackles he makes is incredible and his tone setting is always so on point. I hope that we graduate on the academy products to take after him and start training some depth behind him with the same poise, approach, and ferocity.
If 2020 brings similar disappointment as the last three years I fear that it will be something because of the midfield. We just don’t have enough creativity outside of Maxi. I’d imagine that the club sees this obvious Maxi dependence as well and has the scouting network already churning to find someone new. If we go the entire season without a significant addition here I just don’t see how we can go all the way in the playoffs. We’ve been surprisingly lucky with injuries over the past three years.
Offensively, we’re stacked. The biggest threat to the offensive production of this team is City deciding to move Taty to greener European pastures in the summer transfer window. Mitrita and Heber are going to continue to improve as they get more comfortable with NYC and the system. If Mitrita can keep up his end of year form and can have better pass connections with the rest of the team we can do a lot of damage. Shradi is a great player who always finds a way, personally I love his style but I don’t see how he breaks into a starting striker role with Heber, Mitri, and Taty ahead of him in the XI.My hope is that Ronny finds some creative ways to get all four players involved.
The acquisition of Zelalem is exciting and hopefully will end up being an incredibly worthwhile gamble. Personally, I think a system like CFG is the best place to rehab a career like his. Whether the troubles are mental or physical that are preventing the full potential from manifesting itself you have to think that CFG has the best staff available for the situation.
The arrival of Ronny as the manager is not nearly as inspiring as Patrick or Dome were. You have someone that was struggling to be competitive in Norway coming into a top 4 team in a better league following someone with a trophy case full of UEFA Champions League medals, it’s easy to understand the skepticism. However, I think in this situation the reigns are going to be much tighter than they were with Dome and that the staff under him will be CFG through and through. The bigger coaching acquisition is Nick Cushing (former Man City women’s manager) who is there to make sure that the accepted style is adopted by Ronny. From a motivational perspective, this is a huge freaking job for Ronny. If he figures it out at NYCFC he’s back to being Klopp junior and his stint at Celtic will be a distant memory, I’m sure he’s putting 10000% into this job. If he’s not, Cushing is there to step up to make sure we continue to play attractive and winning soccer.
I love the appointment choice of the new director of football, David Lee. Having seen how both RB and CFG operate has to give him a very unique perspective on how to operate clubs at the highest level from a sporting perspective. I love that NYCFC brought someone in from the spreadsheet side and not a retired player. Building a team is different than actually playing and I’m hoping that we got someone like Darryl Morey (Houston Rockets GM) or Bob Myers (Warriors GM) rather than Elton Brand(76ers GM.) No disrespect to Reyna, who did a great job, but my guess is that he wasn’t exactly in the spreadsheets doing regressions to understand which players excel at specific skills in specific situations – I hope that David Lee was or was at least close enough to the analytics side to understand it. I trust in our system to see where the club needs to shored up and how long of a leash to give Ronny.
On the topic of Reyna – watching Gio’s success in Germany has been bittersweet. You know that it’s the best for him and for USMNT but part of you imagines what could have been possible in a blue jersey in the Bronx (also kinda wild that CFG didn’t lock him up for Man City). The undeniably good news is that the system that nurtured and trained him is intact and still humming. The youth USMNT teams are full of NYCFC academy products that are continuing to impress. Hopefully we see Gio play in New York in 2026 in a USA jersey.
When it comes to the stadium, where there is smoke there’s fire. I’m sure we’ve all read the reports in the NYT and The Outfield. Based on my reading, CFG is not asking for any signigicant public funding (I think this would obviously be political suicide in NYC) which greatly increases the probability of this actually happening. I honestly am so exhausted by this. Whatever negotiations are happening my hope is that they wrap up before the 2021 mayoral elections which would put the entire process in limbo.
This year with CCL I’m excited to see how well we stack up against some of the stronger central American sides, but it does feel like the competition would be bigger if the Liga MX and MLS clubs were invited into Copa Libertadores. I understand the difficulty with the travel, but consistent competition in a tournament with groups and a proper playoff is how I believe NYCFC will truly become great. Being included this year, even with the stadium debacle, is fantastic for a young club.
In terms of the fans, I know the numbers are down but everyone I recognize is still there. The people I saw in the stands in ‘15 are still there. My hope is that NYCFC continues to give members easy ways to bring friends to the stadium, especially to the bleacher section – there’s nothing like it in the five boroughs. That’s where the heart beat is, that is still going strong and better than ever. The online following of the team for the hardcore fans has been as good as it’s ever been. I thought that the free admission cards promotion should be in play for the Red Bulls game this year. Whatever the financial loss would be for the club will hopefully pay MASSIVE dividends, outside of Rangers vs. Islanders there’s nothing like Hudson River Derby (pipe down Nets fans no one cares). We’re still here and we’ll continue to be, stadium be damned.
The club has continued to produce very exciting teams that produce goals and win points. The biggest hope remains in the academy where the academy starlets were frustrating grown men in Orlando and Los Angeles and even scoring goals. The academy has won back to back titles in fairly dominant fashion and I’m hoping that we start to see the fruits of efforts there this year with Gray and Haak coming up big. Fundamentally, aside from Maxi – the squad, especially in the forward spots, is young.
More competition will not be the downfall of NYCFC, it will make us stronger and will only make following the team more fun. I’m totally fine with us not blowing up the club because we lost in a single elimination playoff – at the end of the day we scored the most goals in the conference, were the 1st seed, have stud strikers, and a top defensive back line with a national team goalie. That is what makes me so hopeful about our future. That’s why I stand here confident that the STATE OF THE CLUB is strong.
I love Google Search Console. It provides the best, actual information on how your site is showing up on Google. However, getting information out of Google Search Console is almost impossible if you want to get all of your information out of the pre-built dashboard. This is a guide on how to get the following information out of Google Search Console for larger sites. It has the side benefit of getting you set up to work with Google Search Console data in python for any additional analysis you may want to work on :).
Specifically, this guide teaches you how to pull the following information on a per day, query, and landing page basis:
Impressions
Clicks
Position
Click-through rate
Using the following technologies:
Python
Google’s Webmaster API
Jupyter (an open-source framework for data analysis)
Before getting started, you’ll need to download the code here (https://github.com/odagayev/jupyter_GSC)
This guide is not perfect – see something say something friends; please DM me on Twitter if something doesn’t make sense or can be improved. Anyways, see the instructions below:
Part 1 (this is for Python novices or people that are not proficients coders yet!)
Install Python3 & Pip – this is actually a lot harder than it needs to be for folks just starting out. I don’t fully have a grasp on all of the dependencies and permissions so I’m gonna link the guides that I found useful during my experience.
Type the following to install all dependencies on your machine:
pip install -r requirements.txt
This should kick off a ton of installations of dependencies.
Launch the Jupyter notebook by typing jupyter notebook
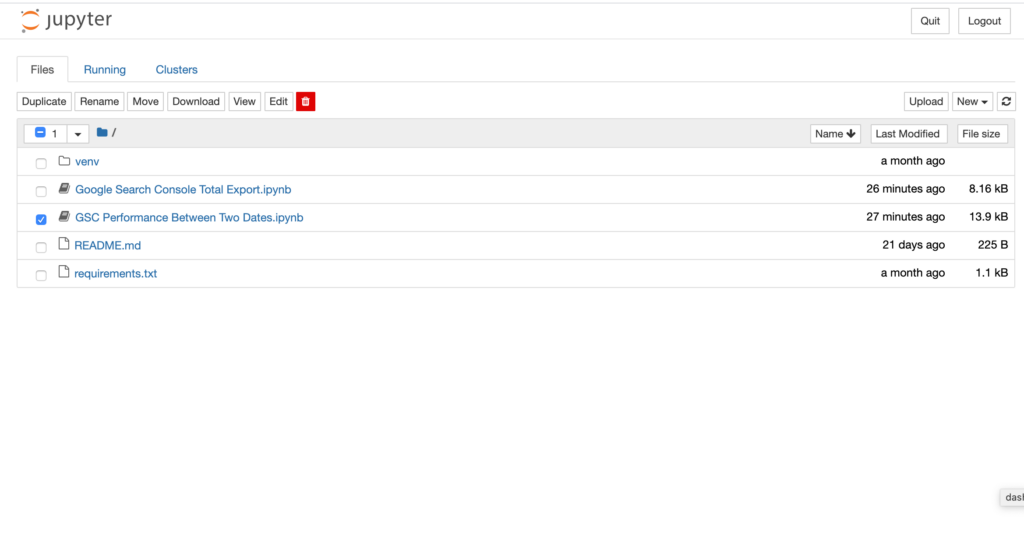
You should see something that resembles the following address in your terminal console: 127.0.0.1. Copy and paste that address into your address field in your browser. You should see something like the below in your browser:
Jupyter notebook screenshot.
Click into the “Google Search Console Total Export.ipynb” file
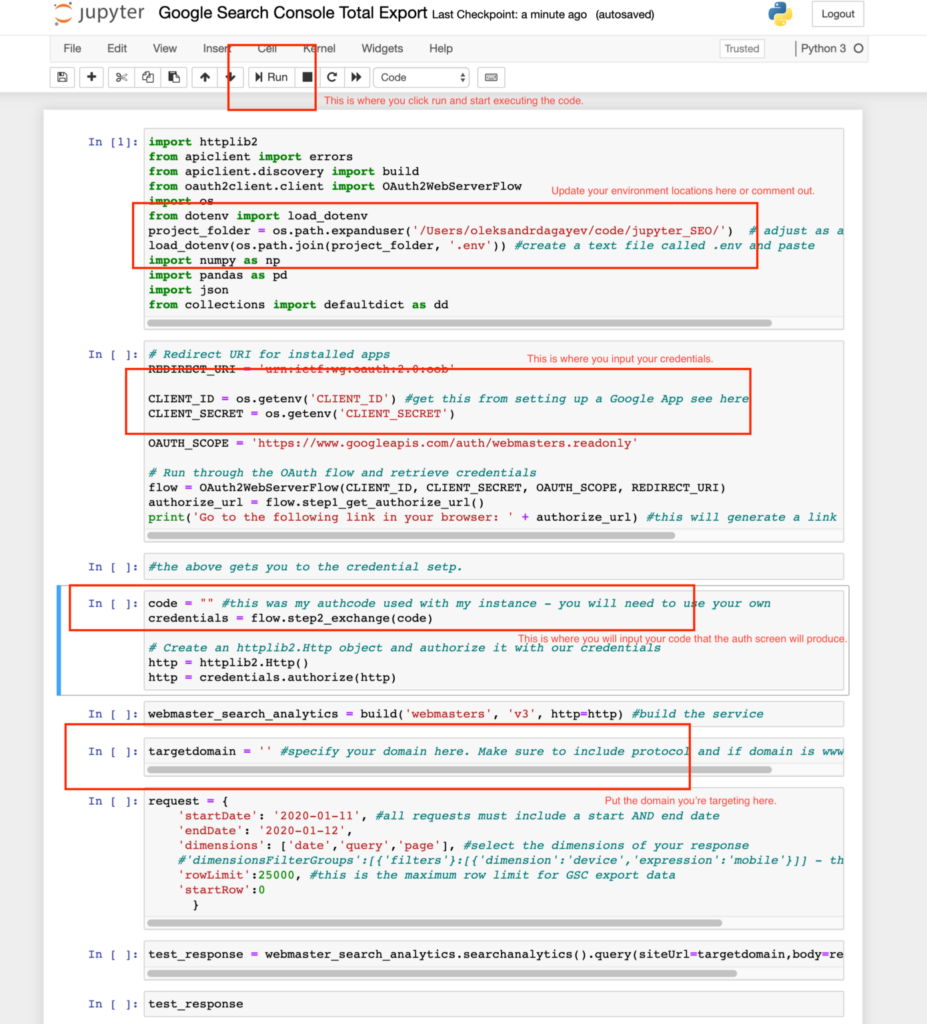
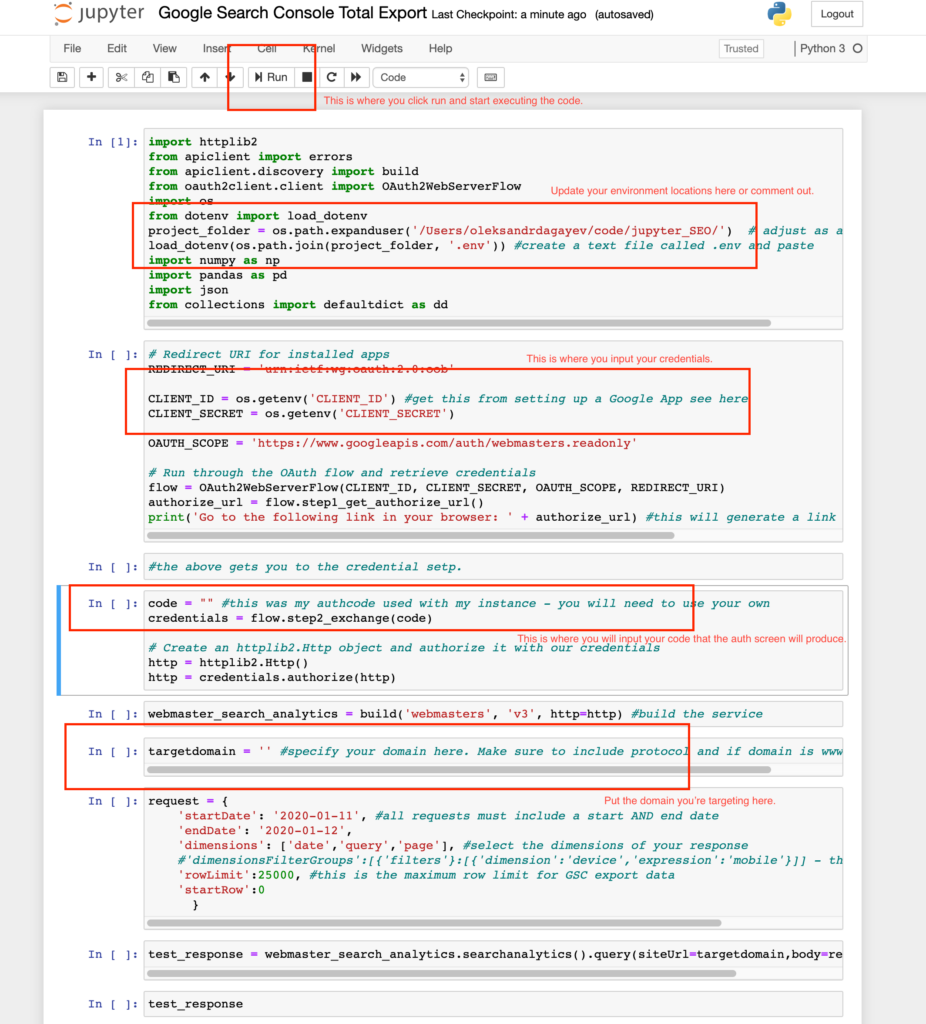
A Jupyter Notebook works on a step by step basis. It works by going step by step through each “cell”. This makes it great for working with data and I think makes it easy for novices to follow code as it is being executed. Update the project folder value as is shown in the screenshot below and either create a .env file with the CLIENT_ID and CLIENT_SECRET values or paste those values directly into the script. If you’re pasting the values directly into the script put a # value in front of the project_folder & load_dotenv lines in cell 1.
The setup step for credentialing inside a Jupyter notebook.
Click on the generated link and you should be taken to an authentication screen by Google. Complete the authentication and copy the code and paste it into where it says code = "" in between the "". Hit run until you get to the target domain step. In the code you have everything set up to make an API call at this point. Below we’re going to configure the actual request!
In between the parenthesis at target domain enter the domain you are targeting. Make sure to include the appropriate protocol and whether the domain is on www. or not. Lastly, make sure you actually have access to this domain in Search Console.
Within the API request parameters, I outlined where to input values for dates and what dimensions you want. I recommend keeping this request as is on your first time through the process so that you can get the hang of it.
Continue to hit Run until you get to test_response and run that cell. You should see a JSON object of the response and recognize the data. Conversely, if something got messed up during credentialing or creation of the request you should see an error message returned.
The next cell puts the JSON response into a dictionary and then the cell after that puts it into a nice table (this is called a pandas DataFrame in Jupyter speak but for our purposes, this is just a table).
The next five cells define a function that iterates over the returned data and makes several requests so that you can get all of your search data out. This is done because Google only returns up to 25,000 data points at a time. So for larger sites, we’re making several requests until we don’t get 25,000 data points.
The last line in the code pushes the table into a nice CSV. You just have to define file name and location.