
TIME TO RUN THROUGH THIS GUIDE AND GET USEFUL DATA: Under 10 minutes.
This guide is intended for those that are interested in harnessing the power for Google’s NLP APIs and want to understand what topics are missing from their content. The end product of this guide is a technical analysis of what topics your content covers vs. what topics competitor content covers.
- Google Natural Language APIs
- Google Colab
- Python
What’s required:
- Zero technical background
- Creating Google API credentials
- The ability to copy & paste
The output is a nice .csv file that you can give to your content team and let them know what other pieces of content are still needed to be included or may be missing.
As always, this guide is not perfect. If you have questions, the best place to reach me is on Twitter (@oops89). Anyways, see the below:
- Go here (https://colab.research.google.com/drive/1WE7aMVsWDw-GoqXOdiT18-CqjwcPJaH_#scrollTo=qkSW-0qyYlcP)
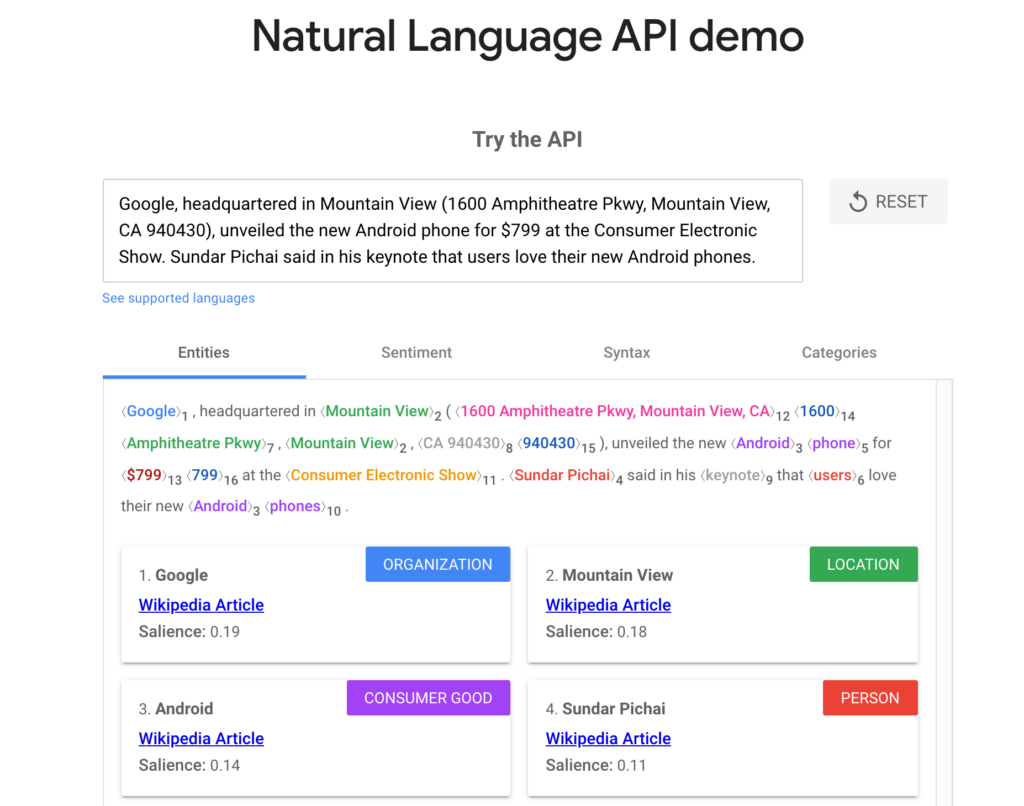
- This is a code page of Google’s Colab framework which lets your run code FOR FREE on their cloud machines without ANY significant overhead. What this means for you is NO SET UP OF ANYTHING – IT JUST WORKS. When you click this, it should take you to a page that looks like the below.
- Click play on the very first line of code – this should initialize the initial pieces of software that you’ll need.
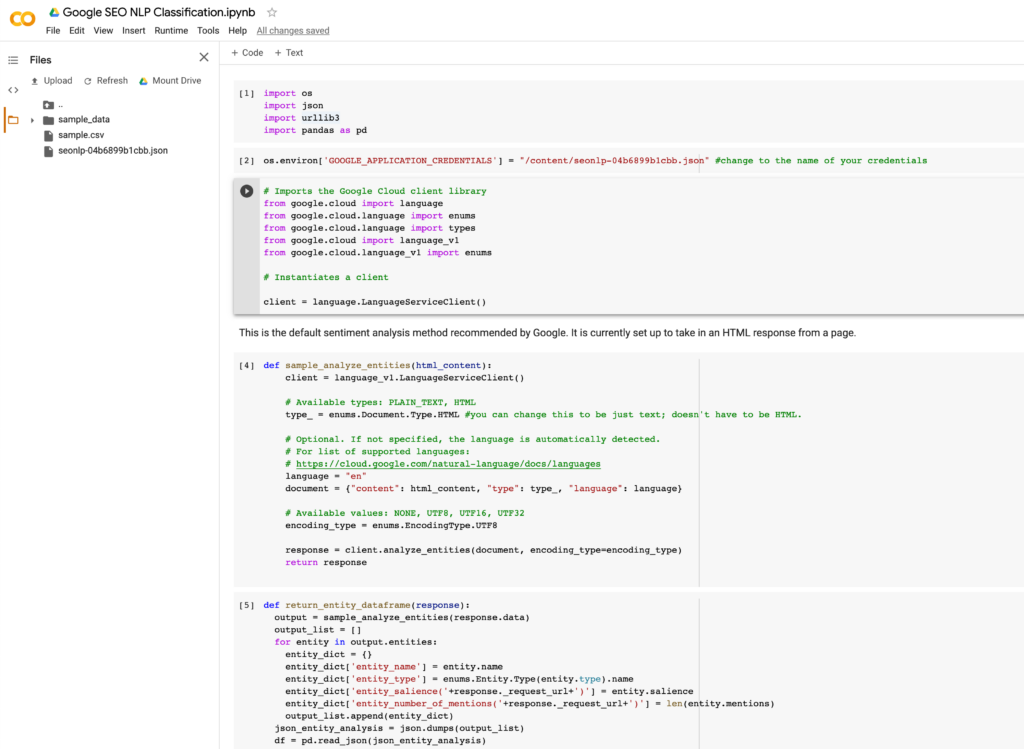
- Once you’re in, click on File & “Save a copy in Drive” – you won’t be able to make edits to my version.
- Go here (https://cloud.google.com/natural-language/docs/quickstart) and follow the steps to Set Up a project. This should be step 1 at the time of writing this guide.
- Once you set up the project, you’ll need credentials. The way to get to credetials is to click on the hamburger menu on the upper left-hand corner then API’s & Services > Credentials.
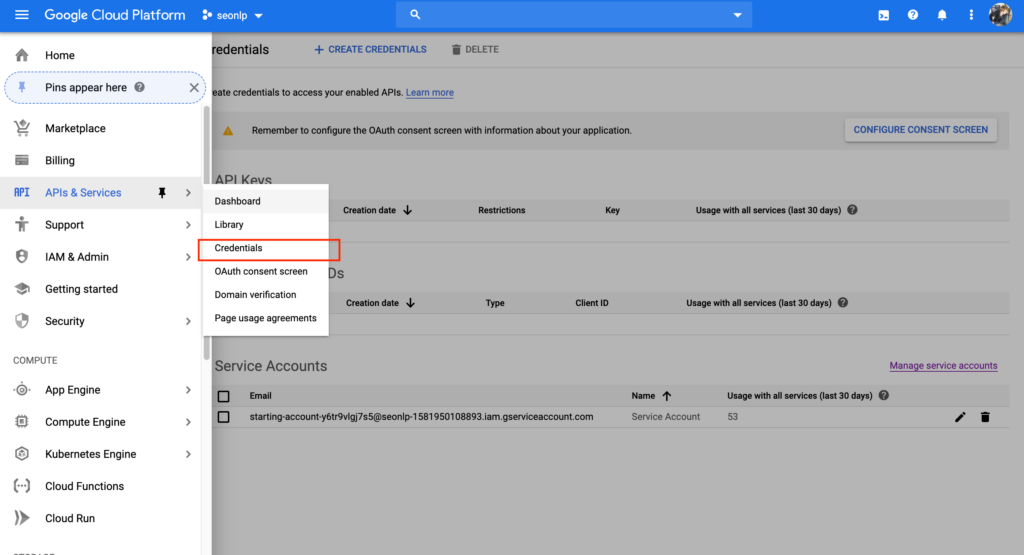
- Click on “Manage service accounts” and follow the steps to create a service account. At the of this set up process you should be given a .json file that will serve as authentication.
- Jump back to the Colab window and click on the folder and then click on “Upload”. Upload the .json authentication file.
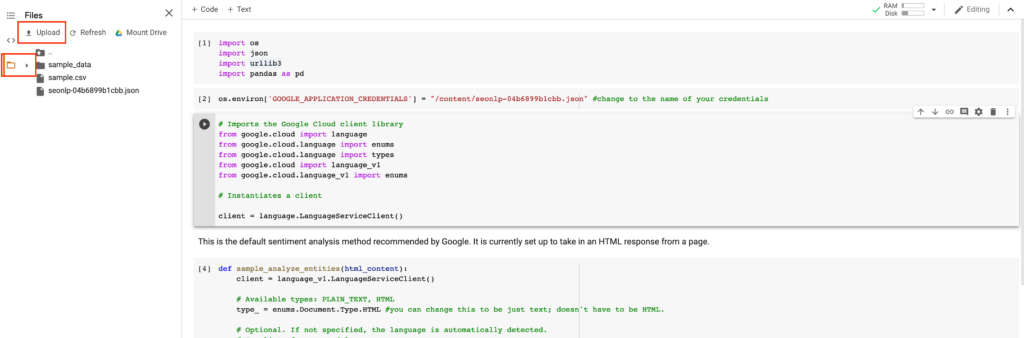
- Change line 2 in the Colab notebook to exactly match the file name of your .json file. This is important to get right because this is what it is used for authentication.
- Keep hitting play until you get to the below. This is where you’ll need to put in the URLs that you would like to use. By default, I used three articles that are about the keto diet as an illustrative example – feel free to make this whatever you need.
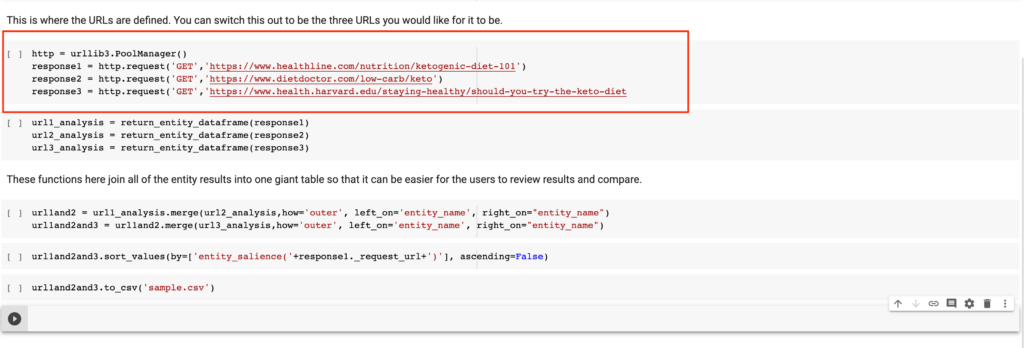
- Once set, continue to hit play. What’s happening now is that the notebook is going to those sites and fetching the HTML on those pages.
- Step 7 in the guide, is actually where the API magic happens and when the NLP API is being hit. The results are all put together into one table that makes them readable.
- Continue to hit play and you should end up with a .csv file called sample.csv. On the left-hand side left click on the file and download it to your computer.
Boom – you’re done with the guide and have actionable data! Now to explain how to use the output. After opening the csv, I recommend sorting largest to smalles on the first “entity_salience” column. The return output is a series of columns organized by the following:
- Name of topic (entity name) – this is the central topic that the NLP API has understood. In this example – the dominant topic was “diet”.
- Entity_salience (URL used) – The salience score for an entity provides information about the importance or centrality of that entity to the entire document text. (this is the Google definition). For us, this is really important because it’s the algorithmic understanding of how important this was to the whole piece.
- Entity_number_of_mentions – this the number of times the topic is mentioned in the text.
- Entity_salience for the 2nd & 3rd URLs
- Entity_number_of_mentions for the 2nd & 3rd URLs
A content producer should be able to look at this data and understand the following with data informing their decision instead of only gut feel:
- Are there any topics that they missed?
- What is the centrality of the topics that the others had discussed?
- How often are others mentioning certain topics in their content?
This method is not perfect and has some known drawbacks that I’ll list below:
- Very random topics such as precise numbers are listed as “topics” by Google’s API. Luckily they have a very low salience score and can be ignored.
- When analyzing HTML, pop-ups and navigation text becomes a problem and is included in the analysis sometimes.
- There is no child-parent relationship defined in the API response in connection to certain entities.
As always, reach out on Twitter if you have any feedback.